8.5.4
Das Claude-Plugin integriert Claude als Prompt-Anbieter in formcycle. Claude steht als eigener Anbietertyp zur Verfügung, nachdem das Claude-Plugin installiert wurde.
Inhalt
Prompt-Verbindungen
Für allgemeine Informationen siehe den Hilfeartikel Prompt-Verbindungen. Im folgenden wird auf die Konfiguration eingegangen, die spezifisch für Claude ist.
|
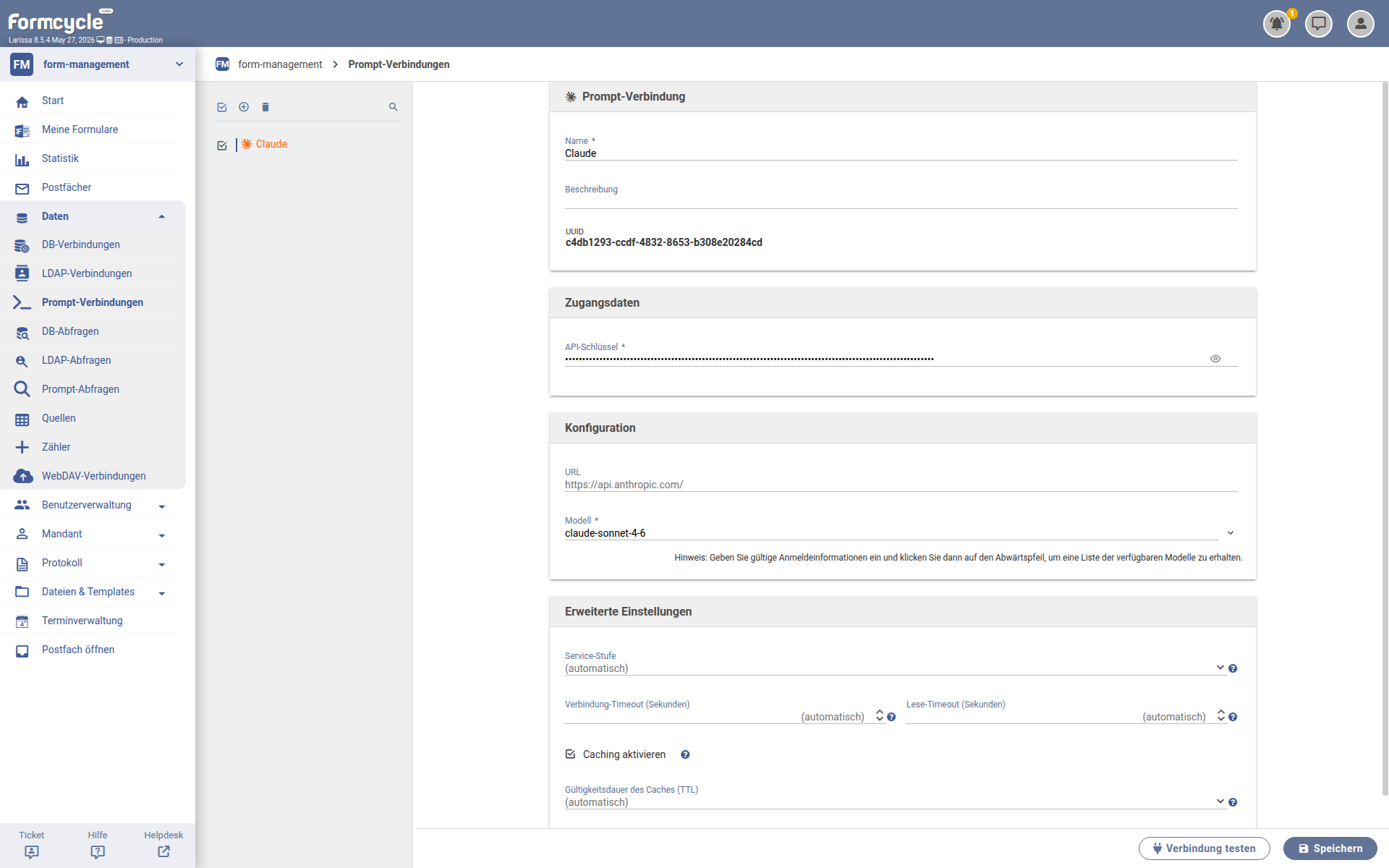
Konfigurationsfelder
- Modell
- Auswahl oder Direkteingabe eines verfügbaren Claude-Modells.
- Service-Stufe
- Bestimmt, ob Prioritätskapazität (falls verfügbar) oder Standardkapazität für Prompts verwendet werden soll.
- Caching aktivieren
- Prompt-Caching optimiert die API-Nutzung, indem es das Fortsetzen ab bestimmten Präfixen in den Prompts ermöglicht. Dies reduziert die Verarbeitungszeit und Kosten für wiederholte Aufgaben oder Prompts mit konsistenten Elementen erheblich.
- Gültigkeitsdauer des Caches (TTL)
- Die Dauer, bis der Cache veraltet ist. Während dieser Zeit können Antworten teilweise aus dem Cache bereitgestellt werden.
Prompt-Abfragen
Für allgemeine Informationen siehe den Hilfeartikel Prompt-Abfragen. Im folgenden wird auf die Konfiguration eingegangen, die spezifisch für Claude ist.
Aufgaben bei Claude
Bei der Verwendung des Claude-Plugins stehen verschiedene Aufgaben zur Auswahl. Die gewählte Aufgabe bestimmt, welche Eingaben möglich sind und in welchem Format das Ergebnis zurückgegeben wird. Je nach Aufgabe unterscheiden sich die verfügbaren Konfigurationsbereiche.
|
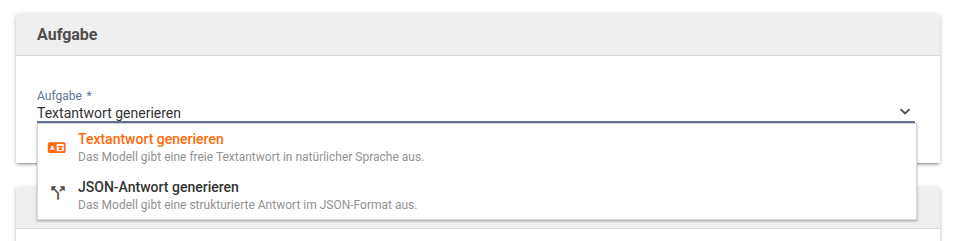
Im Folgenden werden die einzelnen Aufgaben separat beschrieben.
Aufgabe: Textantwort generieren
Die Aufgabe ''Textantwort generieren'' erzeugt eine freie Antwort in natürlicher Sprache. Sie eignet sich für alle Anwendungsfälle, bei denen ein lesbarer Text ausgegeben werden soll, z.B. Erklärungen, Zusammenfassungen oder Formulierungshilfen.
Prompt
Im Bereich Prompt wird definiert, welche Eingabe die KI erhält und wie die Antwort generiert werden soll. Bei dem Claude-Plugin steht eine Websuche zur Verfügung. Das Modell kann daher auf aktuelle Internetinhalte zugreifen.
Dateien
Optional können Dateien in die Prompt-Abfrage eingebunden werden, um zusätzliche Informationen bereitzustellen.
Detaillierte Informationen zur Konfiguration der Bereiche Prompt und Dateien findet man im Hilfeartikel Prompt-Abfragen.
Feinjustierung
In diesem Bereich können optionale Einstellungen angepasst werden, um das Antwortverhalten des Modells gezielt zu steuern. Für die meisten Anwendungsfälle können die Standardwerte beibehalten werden.
|
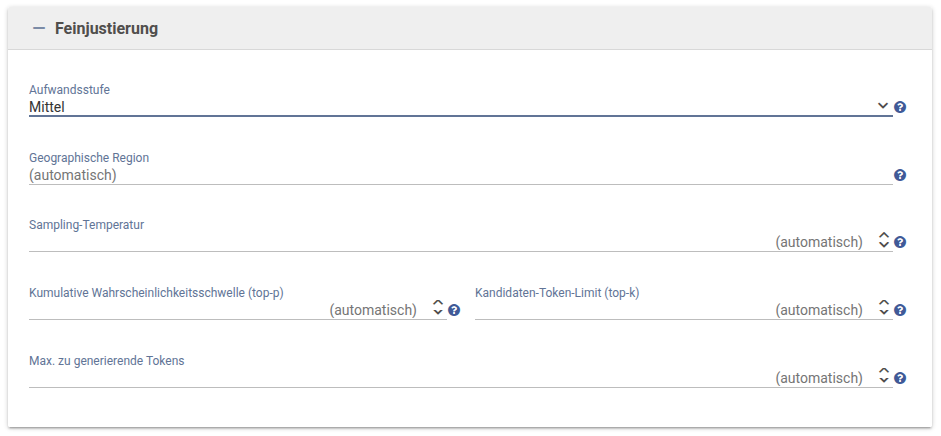
- Aufwandsstufe
- Die Menge an Aufwand, die der Dienst in die Generierung der Antwort stecken soll. Höhere Stufen können zu detaillierteren und genaueren Antworten führen, aber auch die Antwortzeit und die Kosten erhöhen.
- Geographische Region
- Gibt die geographische Region für die Inferenzverarbeitung an. Wenn nicht angegeben, wird die "default_inference_geo" des Arbeitsbereichs verwendet.
- Sampling-Temperatur
- Die Temperatur ist ein Wert, der die Zufälligkeit der Ausgabe steuert. Höhere Werte führen in der Regel zu zufälligeren Ergebnissen, während niedrigere Werte die Ausgabe fokussierter und deterministischer machen.
- Kumulative Wahrscheinlichkeitsschwelle (top-p)
- Die Schwelle für Top-p-Sampling. Das Modell berücksichtigt nur die Tokens mit der höchsten Wahrscheinlichkeitsmasse, d.h. nur die kleinste Menge der wahrscheinlichsten Tokens, deren Wahrscheinlichkeiten zusammen mindestens den Top-p-Wert ergeben. 0,1 bedeutet z.B., dass nur die Tokens mit den obersten 10% der Wahrscheinlichkeitsmasse berücksichtigt werden.
- Kandidaten-Token-Limit (top-k)
- Die Anzahl der wahrscheinlichsten Tokens, die bei der Generierung des nächsten Tokens berücksichtigt werden. 1 bedeutet, dass nur das wahrscheinlichste Token berücksichtigt wird. Dies kann verwendet werden, um die Zufälligkeit zu reduzieren.
- Max. zu generierende Tokens
- Die maximale Anzahl an Tokens, die das Modell in der Antwort generieren darf. Ein Token entspricht etwa 4 Buchstaben oder etwa 3/4 eines Wortes.
Aufgabe: JSON-Antwort generieren
Die Aufgabe ''JSON-Antwort generieren'' erzeugt eine strukturierte Antwort im JSON-Format. Sie eignet sich für Anwendungsfälle, bei denen die Antwort maschinenlesbar sein und weiterverarbeitet werden soll.
Alle weiteren Bereiche wie Prompt, Dateien und Feinjustierung stehen auch bei dieser Aufgabe zur Verfügung und entsprechen in Aufbau und Funktion der Aufgabe ''Textantwort generieren''.
Claude unterstützt nur einen Teil des JSON-Schema-Standards. Das System versucht, das Schema automatisch soweit möglich anzupassen, sodass diese Einschränkungen erfüllt sind. Im Normalfall muss daher nicht darauf geachtet werden. Siehe die Dokumentation der Claude-API für Details bezüglich der Unterstützung von JSON-Schema.
JSON-Schema
Der Abschnitt JSON-Schema ist zusätzlich verfügbar, wenn die Aufgabe ''JSON-Antwort generieren'' ausgewählt wurde. Hier wird definiert, in welcher Struktur das Modell seine Antwort zurückgeben soll.
Die verschiedenen Möglichkeiten zur Definition und Konfiguration des JSON-Schemas werden im Hilfeartikel Prompt-Abfragen ausführlich beschrieben.
War dieser Artikel hilfreich?
Das ist großartig!
Vielen Dank für das Feedback
Leider konnten wir nicht helfen
Vielen Dank für das Feedback
Feedback gesendet
Wir wissen Ihre Bemühungen zu schätzen und werden versuchen, den Artikel zu korrigieren
